Unsere Entwickler haben viel Zeit in neue Optimierungen investiert, um Ihnen bei der Anwendung des Data Directors in der aktuellen Version ein verbessertes Nutzungserlebnis zu bieten. Unser leistungsstarkes Import- und Export-Bundle kommt in Version 3.3 mit den folgenden neuen bzw. überarbeiteten Funktionen und Features:

Zusammenfassung von Datenport-Durchläufen
Für manuell ausgeführte Im- und Exporte gibt es jetzt ein Zusammenfassungsfenster. Dieses bietet eine grafische Benutzeroberfläche, die zeigt, was während der Importe und Exporte passiert ist. Es enthält den Fortschritt, die geänderten Daten (einschließlich der Änderungs-Ansicht) und Fehler (falls welche aufgetreten sind):
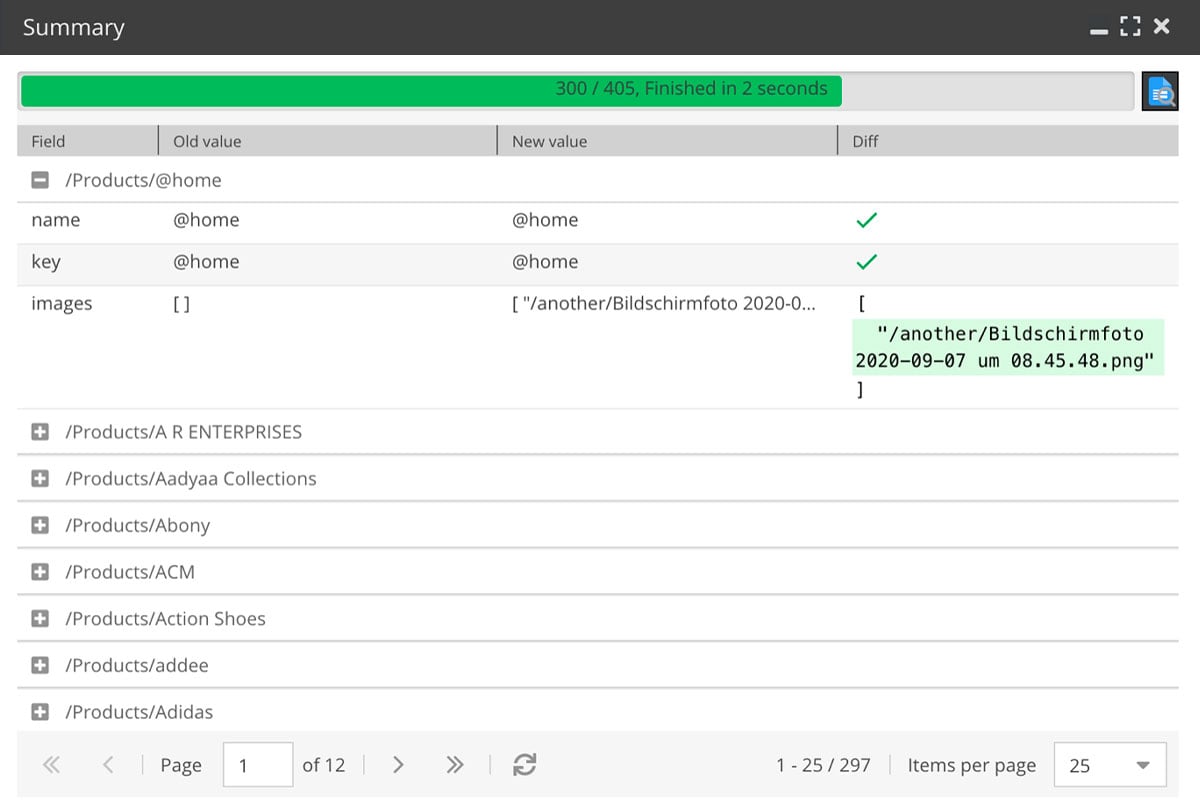
So können auch technisch nicht versierte Personen Dataports ausführen und überprüfen, ob alles ordnungsgemäß ausgeführt wurde.
Intelligentes Logging
Bei nicht manuell gestarteten Im- und Exporten (z.B. Cronjob-Runs, REST-API, ereignisgesteuerte Dataport-Runs), prüft der Logger auf Fehler (puffert aber auch weniger schwerwiegende Logs). Nur, wenn ein Fehler auftritt, werden die gepufferten Logs geschrieben. Wird der Lauf ohne Fehler, Warnungen oder Hinweise erfolgreich beendet, wird keine Protokolldatei gespeichert. Dies reduziert den Speicherplatz für die Protokolldateien und ermöglicht so häufige Anwendungen wie z.B. REST-API-Schnittstellen für reale Website-Benutzer.
Darüber hinaus implementiert diese Version Lazy Logging: Die Log-Informationen werden nur dann generiert, wenn der Log tatsächlich geschrieben werden soll. Vorher wurde der Log auch generiert, wenn das Log am Ende gar nicht gespeichert wurde (z.B. Debug-Logs) – doch für Log-Level, die ohnehin nicht geloggt werden, war der ganze Aufwand für die Generierung der Log-Informationen (z.B. Objekt-Serialisierung, JSON-Encoding etc.) überflüssig.
Effizienterer Queue-Prozessor
Importe für denselben Dataport, aber unterschiedliche Importressourcen werden jetzt parallel ausgeführt. Dadurch werden automatische Dataports (z.B. Datenqualität) bei Massenimporten deutlich schneller ausgeführt: Der Warteschlangenprozessor passt nun häufiger die Anzahl der parallelen Prozesse an. Außerdem wird die Anzahl der maximalen parallelen Prozesse in den Website-Einstellungen anstatt im Cache gespeichert. Dies verhindert, dass die Anzahl zurückgesetzt wird, wenn der Cache geleert wird. Nützlicher Nebeneffekt: Es ist möglich, die Anzahl der maximalen parallelen Prozesse manuell zu erhöhen.
UI-Änderungen
Dataport-Baum
- Markierung von Dataports, die seit mehr als 14 Tagen nicht mehr verwendet wurden, um das Aufräumen alter Dataports zu unterstützen.
- Kennzeichnung von Dataports mit Fehlern bei den letzten Läufen in roter Farbe, um sofort zu erkennen, welche Dataports Probleme verursachen.
- Rollen, die einen Dataport als Favorit im Kontextmenü des Datenport-Baums haben, werden hierarchisch angezeigt, um eine bessere Übersicht zu geben.
- Zur Gruppierung von Dataports mit gemeinsamem Präfix wird die Groß- und Kleinschreibung des ersten Buchstabens ignoriert.
Dataport-Konfiguration
- Unterstützung von Massenbearbeitung für Rohdatenfelder.
Attribut-Zuordnung
- Bessere Vorschau und Erklärung, wenn das Schlüsselfeld ein Array liefert.
- Unterstützung des Mappings von creationDate, modificationDate für Asset-Importe.
- Zeigt keine einzelnen Objekt-Brick-Felder, wenn es mehr als 50 gibt. In diesem Fall ist das Mapping nur noch über den Objekt-Brick-Container möglich, sonst ist die Ladezeit zu lang (nichtsdestotrotz wird an weiterer Optimierung der Ladezeit des Attributmappings gearbeitet).
Vorschau-Panel
- Unterstützung der Mehrfachauswahl für die Verarbeitung mehrerer Rohdatenelemente (zum Testen).
- Unterstützung der Mehrfachauswahl zum Öffnen mehrerer Objekte durch Verweis auf Schlüsselfelder.
- Hervorhebung von Daten, in denen der Suchbegriff gefunden wird, anstatt Spalten auszublenden, in denen der Suchbegriff nicht gefunden wird.
Objektbearbeitungsfeld/Gitterfeld
- Anzeige der verfügbaren Exporte/Importe für ein Objekt in der Symbolleiste der Objektbearbeitung.
- Grid-Export: Immer „Content-Disposition: attachment“ setzen, da Grid-Exporte immer in demselben Fenster wie Pimcore ausgeführt werden. Wenn die Ergebnis-Callback-Funktion kein Ergebnisdokument erzeugte (sondern z.B. nur einen weiteren Dataport in die Warteschlange stellt), wurde eine leere Seite im Pimcore-Tab geöffnet. Stattdessen gibt es jetzt immer einen Download für Grid-Exporte: Wenn der Dataport kein Antwortdokument erzeugt, wird ein Dummy-Dokument mit „Dataport erfolgreich ausgeführt“ bereitgestellt.
Andere Änderungen
- XML-Importe: Protokollierung von XML-Fehlern.
- Unterstützung des Imports aus FTPS-Ressourcen.
- Verhinderung des Missbrauchs von programmatisch gestarteten Dataports:
Wenn Dataports programmatisch gestartet werden, konnte es passieren, dass zu viele Prozesse ausgeführt wurden und der Server abstürzte. Jetzt wird zuerst geprüft, ob und wie viele Prozesse an einem bestimmten Dataport laufen (relativ zur CPU-Anzahl). Sind es zu viele, werden neue Prozesse automatisch zur Warteschlange hinzugefügt, statt ausgeführt zu werden.
Das kann z.B. passieren, wenn ein anderer Dataport von der Ergebnis-Callback-Funktion über Cli::execInBackground('bin/console dd:complete 123') getriggert wird – eigentlich verhindert das „start dependent dataport“-Template dies. Wenn Entwickler:innen dieses Template nicht verwendet, konnten sie bisher in diese Falle tappen. Diese Gefahr ist nun jedoch gebannt. - Unterstützung des Imports in den Feldtyp „block“.
- Unterstützung des Imports von Strings, die wie JSON aussehen, aber ohne Parsing behandelt werden sollen, z.B. darf [100.00] nicht in [100] umgewandelt werden.
- Automatische Installation von Migrationen im Wartungsscript.
Dadurch ist das Updaten leichter, weil man die Migrationen nicht mehr manuell ausführen muss. - Automatische Löschung von Elementen in der Warteschlange, die älter als drei Tage sind. Ursache sind meist falsche Ergebnis-Callback-Funktionen über den Befehl „start dependent dataport“.
- Data Query Selectors: Unterstützung der Suche nach Assets über Metadatenfelder.
- Verbesserung der Erkennung des Wertes und der Einheit von Mengenwertfeldern, wenn diese als String angegeben werden. Die folgenden Zeichenketten wurden erfolgreich getestet, um in Mengenwertfelder importiert zu werden:
- 1,23m
- 1,23 m
- -10°C
- 10°C
- 10° C
- 12 Umdrehungen pro Minute
- € 12
- Wenn es Warteschlangen-Prozesse gab, die sich auf gelöschte Datenport-Ressourcen-IDs bezogen (z.B. durch Löschen von Rohdaten im Vorschau-Panel), wurden die entsprechenden SQL-Bedingungen als eigenständige Dataport-Ressourcen erstellt. Dies konnte zu einer Vielzahl von Dataport-Ressourcen führen, sodass erst alle überprüft werden mussten, bevor ein Objekt gespeichert wurde. Dies verlangsamte die Speicherprozesse.
- Verhinderung einer falschen E-Mail-Benachrichtigung „Queue-Prozessor konnte nicht gestartet werden“.
- Verwendung von league/flysystem-sftp-v3 anstelle von league/flysystem-sftp → PHP 8.1 Kompatibilität.
- Asset-Importe: Vermeidung eines Fehlers beim Importieren von Ordnern.
- Unterstützung des speziellen Rohdatenfeld-Selektors „__count“, um die Anzahl der Datensätze in der aktuellen Importdatei zu ermitteln.
- Tagging von Elementen bei Importfehlern, um die Suche nach Importproblemen zu erleichtern.
- Unterstützung des Selektors „__all“ für XML-Ressourcen, um komplette Rohdaten in einem Rohdatenfeld zu erhalten.
- Bereitstellung eines Währungsumrechnungsdienstes, wenn Mengenwertfelder mit der Option „Nicht vorhandene Einheiten automatisch erstellen“ importiert werden.
- Unterstützung der automatischen Ausführung von Dataports ohne Datenquelle (z.B. als Pseudo-Cronjobs).
- Hinzufügen einer Callback-Funktionsvorlage für die Initialisierungsfunktion zur Begrenzung der Häufigkeit von Dataports, z.B. Ausführung nur alle x Stunden (Pseudo-Cronjob).
- Unterstützung von CORS-Preflight-Anfragen für REST-API-Endpunkte.
Unsere Data Director Tutorials
Weitere hilfreiche Tipps zur Anwendung des Pimcore Data Directors bieten die detailgenauen in der Blackbit Academy.
Sie kennen den Data Director noch nicht?
Neugierig auf unser Pimcore Import- und Export-Bundle? Dann informieren Sie sich in unserem Shop und über das Import- und Export-Bundle für Pimcore.
In einer individuellen Demo zeigen wir Ihnen gerne, welche Möglichkeiten der Data Director Ihnen bietet. Sprechen Sie uns jetzt an!

Lassen Sie uns Feedback da