 The first Data Director update after the launch of Pimcore X again provides users of the export and import bundle with a number of improvements and new features.
The first Data Director update after the launch of Pimcore X again provides users of the export and import bundle with a number of improvements and new features.
Learn in detail which innovations our developers have made in the latest version of the Data Director and from which improvements you can benefit with version 2.5.0:
Pimcore 10 compatibility
Version 2.5.0 is fully compatible with Pimcore 10 - with the small limitation that not all libraries used are compatible with PHP 8. For Pimcore 10, you currently need to install Data Director via Composer with --ignore-platform-reqs. However, we are working on PHP 8 compatibility - also with regard to the libraries used.
Grid filtered exports
It is now possible to use the grid view (folder view) for filtering and then export the objects selected in it. This way you can perform ad-hoc filtered exports without having to enter a SQL condition. To start the export, there is a new option "Data Director Export" in the drop-down menu of the "CSV Export" button.
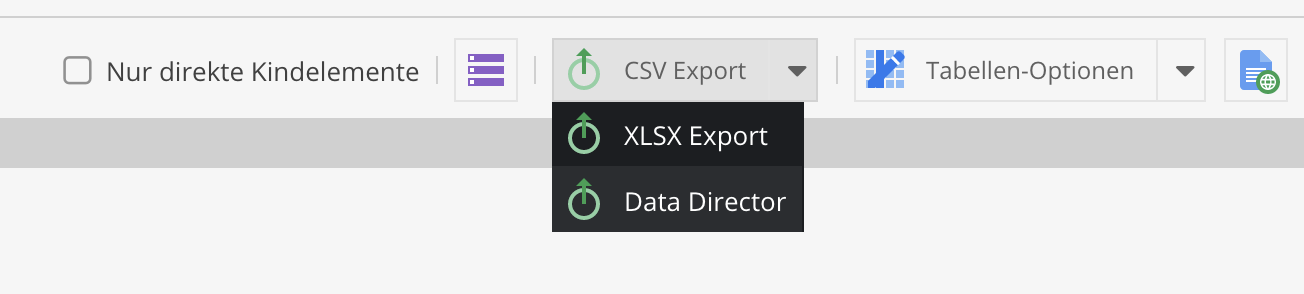
In the following modal window you can select the dataport to be used for the export (only compatible exports for the selected grid data object class will be displayed).
.png?width=1212&name=MicrosoftTeams-image%20(18).png)
Refactoring of (automatic) exports for API usage
Previously, raw data for automatic exports was updated for each previously executed SQL condition. This resulted in poor performance when saving objects. This has been completely refactored: For automatic exports, raw data is now updated only for the configured Dataport SQL condition (and for each language). The updated raw data is then also used for the previously executed SQL conditions (so that the export data is already prepared when an export with this SQL condition is executed again). This way, the raw data only needs to be extracted once (for each language) and not again and again for all custom SQL conditions.
Also important for API usage: the SQL condition from the query parameter of REST API calls for Pimcore-based dataports now extends the SQL condition in the dataport settings instead of overriding it, so that the dataport condition cannot be easily bypassed (to avoid retrieving unpublished objects, for example).
Accessing Pimcore items via REST API is now only possible if the requesting user has a "view" permission for the items in question.
For incremental exports, the change timestamp of the last successful export is remembered (in the object properties, analogous to imports). When the export is triggered again for this object, its current change timestamp (including potentially inherited fields) is compared with this property, and if the current change timestamp is not more recent, the raw data of the object is not extracted again, i.e. not exported. This also allows an automatic incremental export to be performed for all potentially changed objects at once (was previously split between processes of single object exports).
Data Director 2.5.0: Performance optimizations
- Queues of automatic data ports are now processed in parallel. This ensures that a data port with only a few commands in the queue does not have to wait for the queues of other data ports to be processed.
- Reuse of raw data if there is already a raw data item with current hash that has the same modification date as the current object.
- When relational fields are used as key fields for imports, the associated object IDs are resolved beforehand to avoid a query like "WHERE relationalField LIKE '%,123,%'" - instead, the much faster query in the form "o_id IN (345,13,58)" is now executed.
- the same optimization is applied to the SQL condition of Pimcore-based data ports.
- Unnecessary locks in the Pimcore parser have been removed.
- Fixed: Data query selectors were evaluated twice if they did not return a Concrete Object.
- Relations cache is now also used for data query selectors that return data from the queried object.
- 600% performance increase for image gallery/(extended) many-to-many relations asset mapping imports.
- When checking for changes to an object during an import, fields are sorted first based on whether they are mapped or not. Thus, in attribute mapping, mapped fields are checked first because it is more likely that their values have been changed than those of unmapped fields.
Raw data extraction
- Added option to skip versioning for asset imports.
- Added support for glob expressions in combination with asset folders as import resource, e.g. /import/*.csv if /import is a Pimcore asset folder.
Attribute mapping
- Index is recommended when callback function data query selector is used.
- History panel not automatically reloaded when dataport runs are filtered (searched) or when not currently showing page 1 -> easier to search for a specific run.
- Added template for adding metadata to assets.
History and Import panel
- SQL condition field is automatically focused when Pimcore-based dataports are manually launched from Pimcore backend.
- Retain SQL condition from previous run to make it easier to run the same import/export multiple times (e.g. when setting up/testing dataports).
Other changes in version 2.5.0
- Extended many-to-many relationship are supported as key field (stored differently in database than (extended) many-to-many object relationship).
- Increased "fieldNo" column size so that 3-digit numbers are not truncated.
- Add callback function template to generate absolute asset/thumbnail URL.
- Bugfix: Optimize inheritance: more efficient check for parent objects if values have actually been changed before saving them.
- More accurate field value comparison when checking if an object has been changed by an import, to detect a change from 0 to ''.
- Element type and class name in serializer for relational fields are provided.
- Bugfix: overlapping imports: raw data elements already processed are not processed again.
- Use of an error-tolerant JSON decoder to avoid aborting the whole import in case of incorrect character set encoding of the import document.
- Bugfix: Attribute mapping preview overlooked configured asset source folder (actual import worked correctly).
- Preventing multiple mapping of the same asset to the image gallery and many-to-many relation.
- Prevention of multiple parallel requests to update the history panel.
- Bugfix: When using a relative folder path as import resource, deleting the asset file after import (when invoked with --rm) now works.
- Imports with --force no longer check if the item is currently locked for editing.
- Faster showing and hiding of columns when searching in the Dataport preview window.
- Bugfix: Starting exports by right-clicking on an object in the object tree possible again.
- Bugfix: Raw data import is assigned the correct logger object and logs appear in import run logs.
- Use of application_logs table (if used in Data Director) to find worst log level.
- Maximum runtime when searching history panel logs avoids timeout even if some items have been found.
- Users who start imports are stored in the versions; allows better traceability of changes.
- Bugfix: Excel import with column index fixed.
- Raw data from currently exported dataport resources are no longer deleted.
- Manually uploaded data are assigned to default dataport resource.
- No stack trace to versions is written to the database.
- Custom logic is used to compare image gallery fields for changes.
- Existing meta column data for extended many-to-many asset relationships is preserved.
- Pimcore documents matching the URL path for REST API requests are no longer loaded.
- Added support for like search (wildcard search) with Data Query Selector.
- Added support for adding items to multiselect fields (instead of always providing all options for selection), now works the same way as for relations, image galleries and other fields with multiselect (previously the set options were always overwritten).
- Bugfix: all raw data is now processed for overlapping imports.
- Data port runs are marked as "aborted" if an uncaught exception occurs or the process is aborted - manually via CLI or automatically by operating system.
- Support for accessing localized fields in the SQL condition of Pimcore-based dataports, e.g. name#en='abc'.
- Support for accessing object brick fields in the SQL condition of Pimcore-based dataports, e.g. brickName.fieldName=123.
- Bugfix: $params['rawItemData'] variable preview in attribute mapping for complex data.
- Bugfix: Demo data for complex XML data.
- Bugfix: XML parsing: multi-value attributes returned [] for child nodes without value.
- INSERT ... IN DUPLICATE KEY for queue items instead of REPLACE INTO to avoid deleting currently processed queue items.
- Support for accessing element fields of ObjectMetadata, ElementMetadata, Hotspotimage objects without adding "element:" to the data query selector.
- Bugfix: Serializer for documents (for Pimcore 4 document structure).
- Existing assets for image galleries/many-to-many relations etc. are only recognized via MD5 hash if the files are stored locally.
- Warning if no key fields are specified.
- Support calling service class methods from a data query selector, e.g. "field:@service_name::method".
- API keys/allowed dataports of other users are now displayed to admins only.
- Bugfix: Fields in dataport configuration are no longer locked when a new dataport is created by a non-admin user.
- Error when generating the auto-complete SQL condition is prevented.
- Added special field "__updated" for file and URL based dataport types.
- Use of the Pimcore user's language for exports if a language is not explicitly specified.
- Support for '' / "" syntax (virtual fields with quotes) to better copy callback functions to reformatting IDEs without messing up the code.
- Field collections are better serialized.
- Null values are included in serializers.
- Added Importer::translate() method to call DeepL/AWS Translate translations for complex field values (e.g. translating field collections).
- Change validation for field collections with localized fields now works.
- Support for exporting all assigned bricks with the Data Director "brickFieldContainer" of the source data class.
More info about the new version of the Data Director as well as a detailed version history can be found on GitHub.
For more info, detailed questions or a consultation about the Data Director Bundle, feel free to contact David Gottschalk anytime.
Leave us feedback